Fine-Tuning LLMs: Understanding LoRA and QLoRA
Large Language Models (LLMs) are powerful tools used in natural language processing, offering versatility across a wide range of tasks. However, while these models are impressive, they often require fine-tuning to perform optimally in specific domains or for particular applications. Fine-tuning allows a pre-trained model to adapt to new data, which enhances its performance in specialized tasks. The challenge, however, is that fine-tuning large models can be computationally expensive and memory-intensive. To tackle this issue, methods such as LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) have been developed to make the fine-tuning process more efficient and accessible.
The Basics
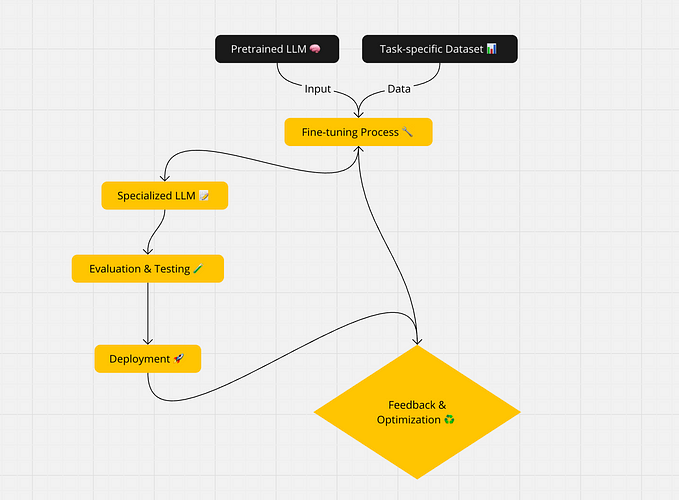
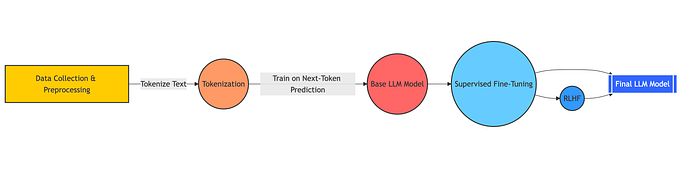
Fine-tuning involves taking a pre-trained model and further training it on a specialized dataset. This process helps the model adapt its internal representations to better fit specific tasks, whether it’s a particular type of language generation, classification, or question answering. However, since LLMs are typically large and resource-heavy, training them from scratch or fine-tuning them fully on all parameters is often not feasible due to the substantial computational and memory costs.
As a result, new techniques have emerged to reduce the cost and complexity of fine-tuning. Two such methods — LoRA and QLoRA — provide innovative approaches to efficiently adapt LLMs for specific tasks.
LoRA: Low-Rank Adaptation
LoRA (Low-Rank Adaptation) is a technique designed to fine-tune large models in a more efficient and memory-friendly way. Instead of modifying all the parameters of a pre-trained model, LoRA introduces low-rank matrices into the model layers.
How LoRA Works
- Parameter-Efficient: Rather than updating all the parameters of the model, LoRA only fine-tunes a small subset by adding low-rank matrices. These matrices are small in size but powerful enough to capture the relevant features for a specific task.
- Memory Savings: By adding low-rank matrices instead of modifying the core model parameters, LoRA reduces the memory requirements for fine-tuning. This is particularly useful when working with very large models.
- Modular Adaptation: LoRA’s low-rank matrices are modular, meaning different adaptation matrices can be added for different tasks. For example, you could add separate matrices for sentiment analysis and machine translation, which can be used or turned off depending on the task at hand.
Advantages of LoRA
- Efficiency: LoRA saves memory and computational resources by only fine-tuning a subset of the model’s parameters.
- Flexibility: It allows multiple task-specific fine-tunings to coexist within the same base model, facilitating multi-task learning.
Use Cases
LoRA is ideal for applications where multiple tasks need to be handled by the same model. For example, in multi-task NLP systems, LoRA can enable efficient fine-tuning for tasks like language translation, text classification, or named entity recognition without the need for separate models for each task.
QLoRA: Quantized LoRA
QLoRA is an extension of LoRA that adds another layer of efficiency by incorporating quantization. While LoRA reduces the number of parameters that need to be fine-tuned, QLoRA further compresses the model by quantizing the weights. This reduces memory usage and makes it feasible to fine-tune even larger models.
How QLoRA Works
- Quantization: QLoRA compresses the model’s weights from high-precision formats (like 16-bit floating point numbers) to lower-precision formats (such as 8-bit integers). This reduces the memory footprint significantly while maintaining performance levels close to the original model.
- Low-Rank Adaptation: Like LoRA, QLoRA adds low-rank matrices to the model, but it combines them with quantized weights to further reduce computational demands. This means QLoRA can achieve the same results as LoRA but with a much smaller memory footprint.
- Efficiency at Scale: By combining low-rank adaptation with quantization, QLoRA allows for fine-tuning large models without requiring high-end hardware or large memory capacities. This makes it particularly useful for deploying fine-tuned models in environments with limited resources.
Advantages of QLoRA
- Lower Memory Consumption: Quantization significantly reduces the model’s memory usage, making it more suitable for resource-constrained environments.
- Faster Training and Inference: With smaller weights and reduced computational overhead, QLoRA can achieve faster training and inference times.
- Scalability: QLoRA makes it feasible to fine-tune larger models without hitting memory limits.
Use Cases
QLoRA is especially valuable in scenarios where memory and computational resources are limited but there is still a need to fine-tune large models. This could include mobile devices, edge computing, or any deployment requiring efficient processing at scale.
Conclusion
Fine-tuning is essential for adapting large language models to specific tasks. LoRA and QLoRA offer powerful ways to make this process more efficient and scalable. LoRA focuses on reducing the number of parameters that need to be fine-tuned, while QLoRA takes it a step further by combining low-rank adaptation with quantization to lower memory requirements. Together, these methods make fine-tuning large models more accessible, opening the door for customized, resource-efficient AI applications.